

As a professional trainer from France, I typically teach Next.js to humans. But in this article I am going to teach Next.js to an artificial intelligence.
My goal is to have GitHub Copilot to produce a correct answer when tasked to write a Next.js route handler that streams files.
For those unfamiliar with Next.js vocabulary, a route handler is essentially an API endpoint, written in JavaScript.
Since it should be a trivial piece of code, I want to delegate code writing to my fellow GitHub Copilot.
Why do we need a file streaming route handler in the first place?
Using the /public folder to store and serve files would work, but it would make the picture publicly accessible, which I want to avoid.
Controlling file access necessitates a proper route handler.
File streaming removes the need for copying the image in memory before serving it, which will limit the app RAM consumption at scale.
That's why I want Copilot to generate:
- A proper Next.js Route Handler
- Using a proper file streaming technique
This pattern can be used to stream the user's profile picture or any kind of protected file. When done correctly, it's less than 10 lines of code.
2025/06 update: Vercel docs llms.txt
Vercel has recently introduced a llms.txt file in its documentation,
coupled with a .md version of each content page.
This features is very helpful for documentation ingestion and RAG architectures.
It doesn't seem to exist for Next.js documentation yet, but it would solve some of the issues described in this article.
A failed attempt : direct prompting
Sadly, prompting GitHub Copilot to generate such a route handler doesn't work out-of-the-box.
At the time of writing this article, Copilot is using GPT-4o, and this model doesn't seem to know about Next.js modern "App Router" architecture.
The code it generates is correct Node.js code, but route handlers use a newer syntax based on the web platform instead.
// Prompt:
// "Write a Next.js route handler that streams a file.
// Don't copy the file in memory."
// Output code:
import path from 'path';
// ERR: this is not a route handler...
// This syntax is the older API route syntax
// (so a traditionnal Node.js style middleware)
export default function handler(req, res) {
const filePath = path.resolve(
'.', 'path/to/your/file.txt'
);
const stat = fs.statSync(filePath);
res.writeHead(200, {
'Content-Type': 'text/plain',
'Content-Length': stat.size,
});
const readStream = fs.createReadStream(
filePath
);
readStream.pipe(res);
}That's disappointing. How can we improve the situation? Can we teach an old LLM new tricks?
Context is key
Let's take a minute to understand why GPT-4o, a state-of-the-art model trained on zillions of documents, fails at this relatively simple task.
LLMs are trained at a specific point in time, and since they are massive, this training is costly.
Therefore, LLMs excel at using well-known libraries that have been documented for a long time and discussed extensively. However they suddenly become terrible when asked about more recent technologies.
At the time of writing, this includes Next.js App Router. File streaming, in particular, has never been thoroughly documented.
If you want to produce code using a recently released library, you'll have to provide all relevant documentation as part of the context of your prompt.
I actually wrote the first article demonstrating a proper and modern implementation of file streaming in Next.js App Router, so let's feed it to Copilot.
A cheap context : read the doc as HTML
I've spent half an hour crafting a VS code extension that downloads a web page locally to feed it to Github Copilot's context.
Since there is no direct command to add a file to the context, the extension simply opens the file in a new tab, which Copilot automatically incorporates into its context.
The implementation of this extension went pretty fast, as I leveraged Copilot to generate most of its code. I found myself wishing GPT-4o was that good at generating Next.js route handlers!
Let's give it another shot, this time with a context that does contain the correct answer:
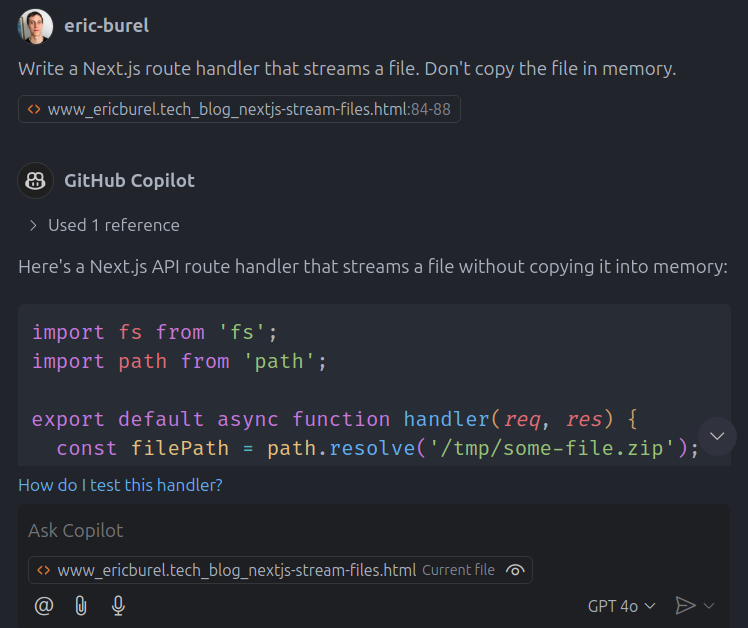
And the issue persists. The code remains unchanged and is still wrong, the context didn't help.
The problem is that my article is a very long piece. In addition, the code formatting solution I use on my blog messes up the HTML structure of code samples.
As a rule of thumb, if a text content is super difficult to read for you, it will be super difficult to read for a language model.
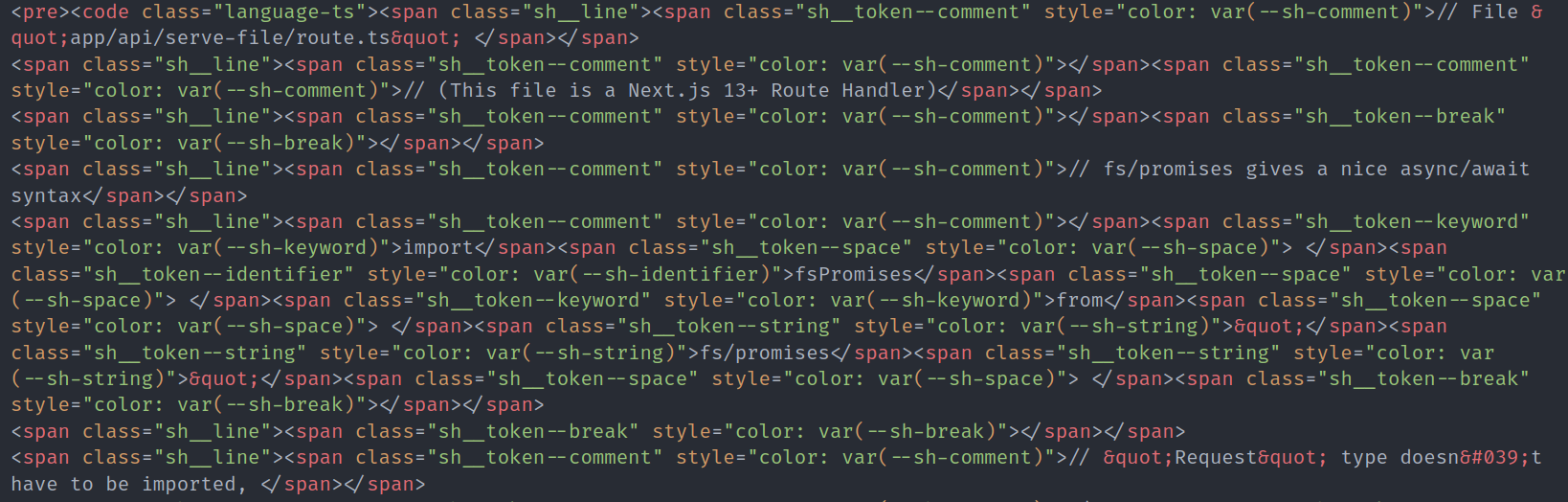 Can you read this code? Your LLM probably can't either.
Can you read this code? Your LLM probably can't either.
HTML content cannot be fed as-is to the model. I have to craft a parsing step.
Converting the page to a more readable format
You know what's a format that is more readable than HTML and that bloggers love? Markdown of course!
Let's see if we get better results when converting the HTML content to markdown.
This is not exactly an original idea. I found it while exploring Cline open source agent's source code. Cline provides many contextualization features and uses Turndown for transforming HTML web pages to markdown.
Cline relies on Anthropic API and leans on the heavy-weight size, so it's still worth crafting my own lightweight solution and keep my experiment going.
After setting up Turndown to process the downloaded article... Still no luck! The result is almost the same as with HTML, context is ignored!
Parsing does remove a lot of unwanted HTML content, such as scripts. There were a few leftovers from HTML conversion still lying around, as Turndown doesn't automatically remove the hydration scripts that Next.js uses for streaming.
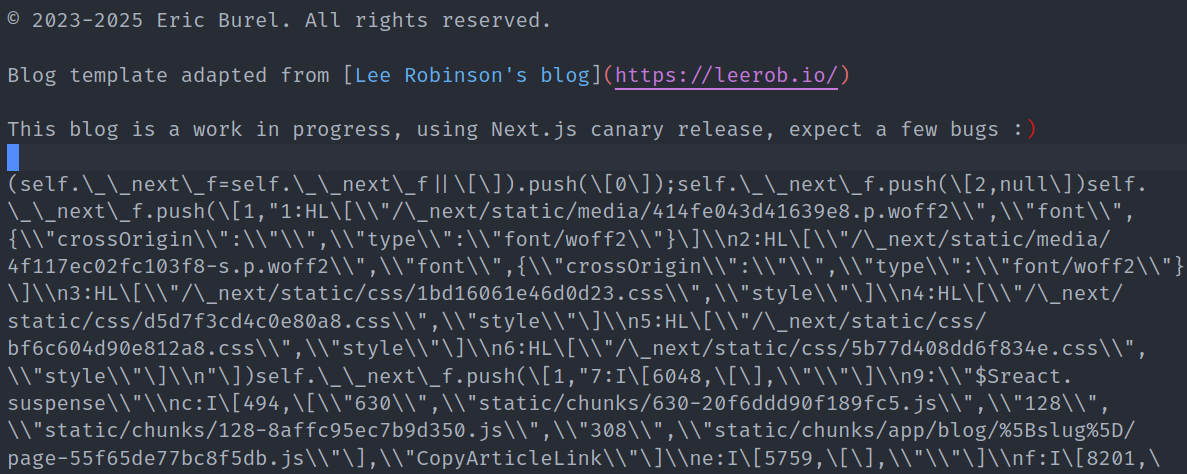
However Markdown conversion doesn't make the article text any shorter, so the correct solution is still drowned into the rest of the article's content.
The next natural step is to assess the effect of extracting smaller chunks out of the web page.
If I literally shove the right solution into Copilot's context and nothing else, we should expect it to output the expected code, right?
Extracting relevant information from the page
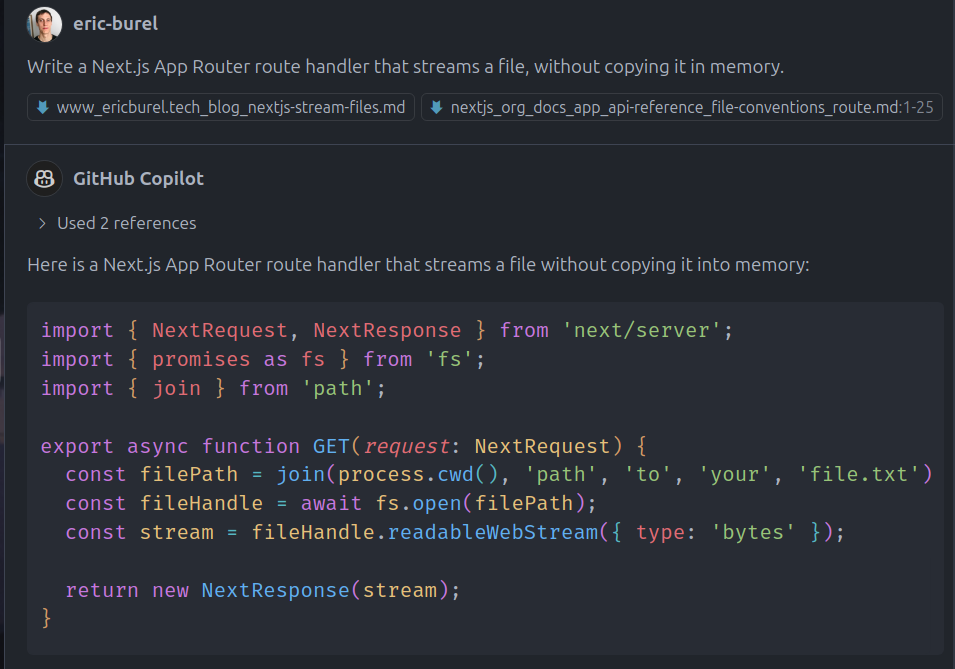
As a final attempt, I've tried to manually isolate relevant sections of both Next.js route handler documentation and my own article.
Even then, I had to alter the prompt to specifically mentions "App router route handlers" and not just route handlers, otherwise Copilot would keep using the API route syntax no matter the context.
And tada! A few hours and many experiments later, I finally generated a proper file streaming route handler using GitHub Copilot!
I didn't go as far as implementing an automated document splitter.
The part that is difficult to automate is not the splitting in itself, but retrieving the most relevant content chunks afterwards for a given prompt. You need to setup a proper semantic search engine for that (aka a RAG architecture), using a paid API or a local LLM.
Moral of this story: your LLM should RTFM
"Language models are few-shot learners". This is the title of the 2020 paper introducing GPT-3. It means that you can teach an LLM to do whatever natural language processing tasks just by showing them a few examples.
Eventhough the most advanced models provide incredible results out-of-the-box, on the daily basis you might get better results with smaller models used in a smarter way.
The cool thing with LLMs is that you only need one model to run semantic searches, translate text, summarize documentation, and output a piece of code blending multiple patterns. They are the smartphones of machine learning!
While I had some trouble to have GPT-4o to output proper Next.js code, Copilot has helped me a lot to structure my experiment code as a VS code extension!
You can find it online on the VS Code Marketplace and contribute on GitHub.
Thanks for reading, I hope you enjoyed the ride!
Here are a few references if you want to deep dive into file streaming with Next.js.
References
Nextpatterns.dev file streaming interactive demo
How to stream files from Next.js Route Handlers - ericburel.tech
French version of the file streaming article - formationnextjs.fr